数据集(data set)
一个大数据集一般我们会把它按照 6:2:2 分成训练集、验证集和测试集。简易的机器学习过程会省去验证集,即 8:2 分成训练集和测试集。
训练集(training set):用来训练模型的数据,机器学习中的学习就是指学习训练集从而形成一个与训练集对应的模型。
测试集(testing set):模型形成后,我们就用测试集来测试看看在真实情况下这个模型能不能用。
验证集(validation set):其实它是归属于训练集的,同样参与模型的学习过程。在模型初步形成后,就用验证集初步评估一下这个模型,如果不太理想,就继续迭代训练。
其中有交叉验证(cross validation)这个概念,交叉是指验证集和训练集交叉,即不断改变这俩的比例,对模型进行综合的训练评估,主要应用是模型选择,特征选择,估计正则参数等
有留一验证(LOOCV):n个点只留一点当验证点,其他n-1个点当训练点;
有K-fold交叉验证:n个点,每次迭代把k个点当验证点,其他n-k个点当训练点;
关于交叉验证详细可参考 极速理解ML交叉验证。
方差-偏差(variance-bias)
模型的泛化误差(generalization error)即训练数据集的损失与一般化的数据集的损失之间的差异,通常由三部分组成:偏差(bias),方差(var),噪声(noise)。
偏差(bias):用所有训练数据集训练出的所有模型所输出的平均值与真实模型输出值之间的差异。
方差(var):不同的训练数据集训练出的模型输出值与真实模型输出值之间的偏离程度。【度量随机变量和其数学期望(即均值)之间的偏离程度,方差越大则偏离越大。】

越是简单的模型偏差(bias)而方差(var)越小;越是复杂的偏差(bias)越小而方差(var)越大。所以这俩形成权衡(tradeoff)。
噪声(noise):包括随机噪声(stochastic error,就是很随机,我们无法建模和估计)和确定噪声(也叫model error,与模型有关!)
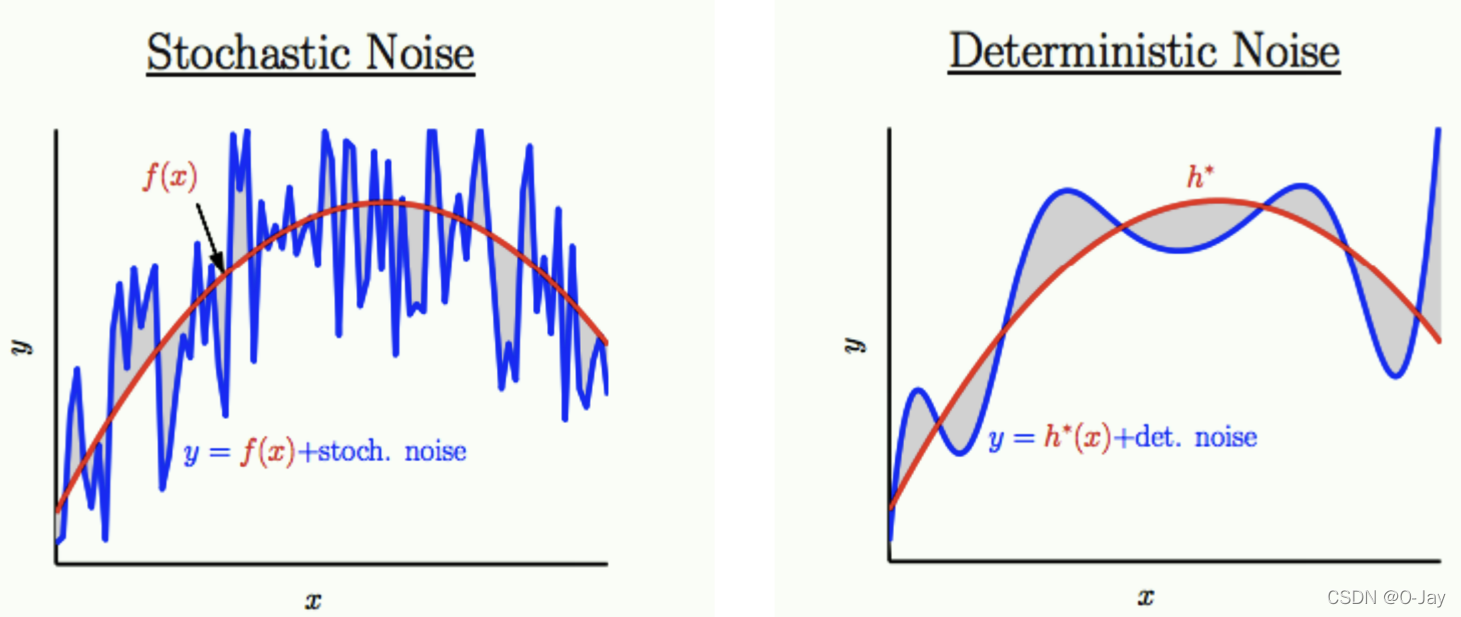
这里再引入两个概念:Ein,Eout
Ein : 训练集内的误差,我们训练的结果就是让它越来越小嘛;
Eout:训练集外的误差,就是训练完的模型在测试集中验验货,看真实情况下模型的误差。
从下面图我们可以发现,对于简单的模型,不需要太多数据就能训练至理想误差,而复杂的模型如果训练数据不足,则Eout会非常大,就是完全不实用,所以模型越复杂(特征越多,即维度越多),我们所需数据就越多(要指数级地增加才能保证收敛性),这就是维度诅咒(Curse of Dimension)。
————————————————
原文链接:https://blog.csdn.net/weixin_45116099/article/details/122524171


发表评论 取消回复